谷歌AI為達目的,把自己的身體改造成了這樣……

文/強化栗
來源:量子位(QbitAI)
強化學習AI打游戲,早就不稀奇了。
智能體在虛擬世界里死去活來,慢慢了解怎樣的策略能讓自己活得更長,得到更多的獎勵。
但AI可能不知道,游戲打不好,也可能是智能體的身體結構有問題。
如果可以一邊學策略,一邊改身材,或許能成就更偉大的強化學習AI。
于是,來自谷歌大腦的David Ha,為自家AI制定了雙管齊下的特殊訓練計劃:
智能體不斷調整自己的身材,比如腿的長度,找到最適合當前任務的結構;同時進行策略訓練。
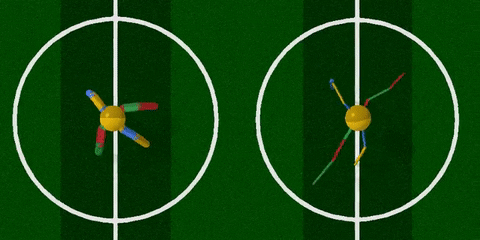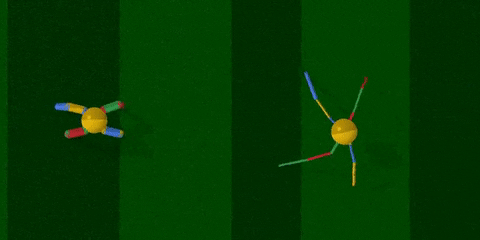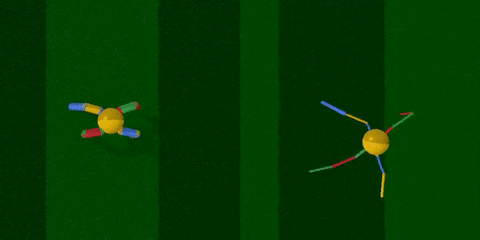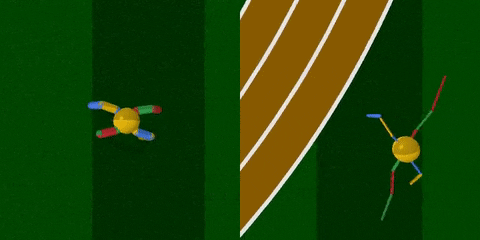
你看,智能體把腿跑細了,速度也快了許多。
除此之外,還可以培養越野能力。
在溝壑縱橫的旅途中,原始身材的智能體時常翻車。

但煉成優雅身型之后,翻車事件幾乎不存在了,策略訓練時間也縮減到原來的30%。
身材科學了,策略也就好學了。
那么,是怎樣的婀娜身段,能在降低時間成本的同時提升性能?再看一會兒你就知道了。
秀外慧中,有何密方?
從前的智能體,形狀結構大都是固定的,只關注策略訓練。可是,系統預先設定的身材,通常都不是 (針對特定任務) 最理想的結構。
因此,如同上文所說,策略要學,身材優化也要一起學。

這樣一來,只用策略網絡的權重參數 (Weight Parameters) 來訓練就不夠了,環境也要參數化。
身體結構特征,比如大腿或小腿的長度、寬度、質量、朝向等等,都是這環境的組成部分。
這里的權重參數w,把策略網絡參數和環境參數向量結合起來,便可以同時培養身材和技巧。
隨著權重w的不斷更新,智能體會越來越強。

身材改造有沒有用?只要和僅學策略、不改結構的智能體比一場,如果獎勵分有提升,就表示AI找到了更適合這個環境的身型。
注意,為了修煉AI的冒險精神,研究人員把高難度動作的獎勵擴大,引導智能體挑戰自我。
身材改造,療效甚好
比賽場地分兩大塊,一是基于Bullet物理引擎的機器人模擬庫Roboschool,二是基于Box2D物理引擎的OpenAI Gym。
兩類環境都經過了參數化,AI可以學著調整里面的參數。
解鎖高分姿勢
首先,來到足球場 (RoboschoolAnt-v1) ,這里的智能體Ant是只四腳怪,每條腿分三截,由兩個關節控制。腿是留給AI調節的,球狀身軀是不可調節的。
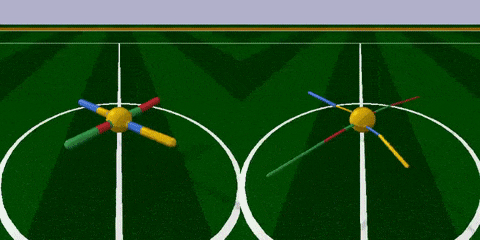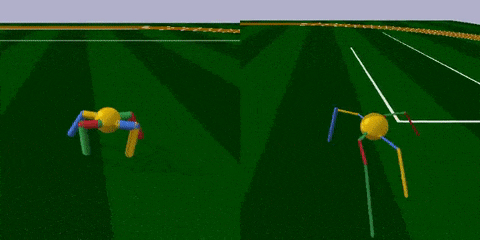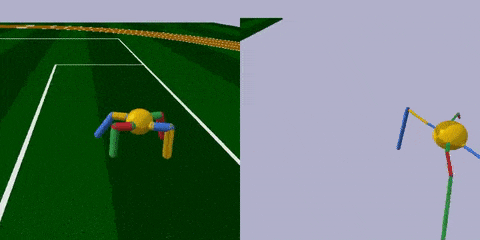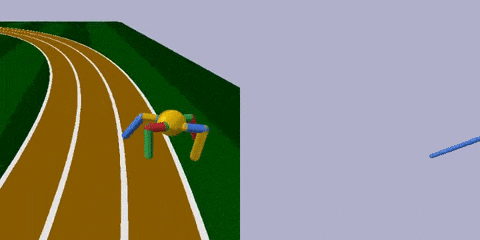
任務很簡單,跑得越遠越好。
經過訓練 (上圖右) ,智能體最明顯的變化是腿部更加細長了,且四條腿長短不一,打破了對稱性。身材改變之后,步頻也加快了許多,長腿怪更早穿過了棕色跑道。
看一下獎勵分:在100次測試里,原始結構的得分是3447 ± 251,而新結構的得分為5789 ± 479,療效顯著。

然后,進入綠地場景 (BipedalWalker-v2,基于Box2D,屬于Gym) 。這里的智能體是兩足的,在“激光雷達”的指引下往前走。
任務是在規定時間內,穿越一片和平的地形 (這是簡單版,充滿障礙物的復雜版見下文) 。用分數來看,100次Rollout超過300分就算任務成功。
原始身材獲得了347分,優化后的身材則有359分。
兩邊任務都成功了,但改造過結構的智能體除了瘦腿之外,兩腿四截的長度都有變化,給了AI彈跳前進的新姿勢。動作看上去更加輕松,分數也高過從前。
好身材,能加速策略學習
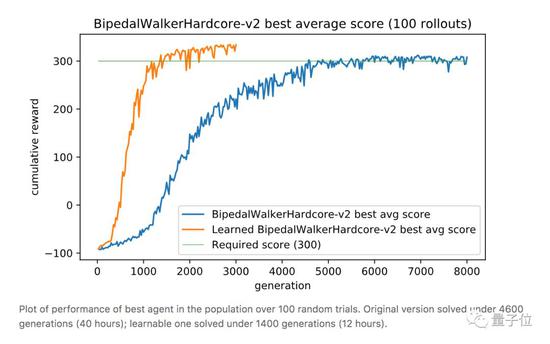
上文綠地的硬核版 (BipedalWalkerHardcore-v2) 在此:路途崎嶇,千山萬壑,一不小心就會墮入深淵。
David Ha要在此證明,強健的身材能為智能體的策略學習帶來加成,而不只是“兩門功課同步學”那樣粗暴的合體。
與之前的全面瘦腿不同,這次智能體的后腿,進化出了厚實的小腿,且長度和溝壑的寬度相近。
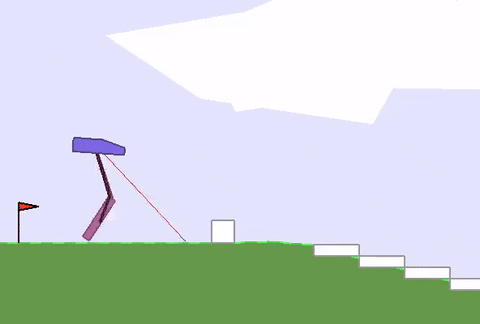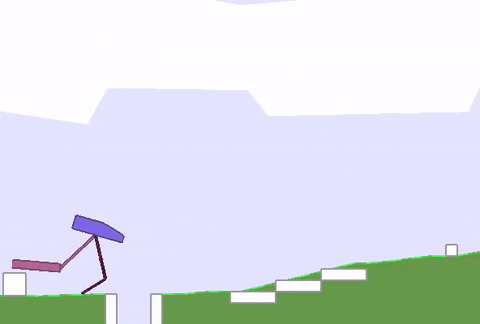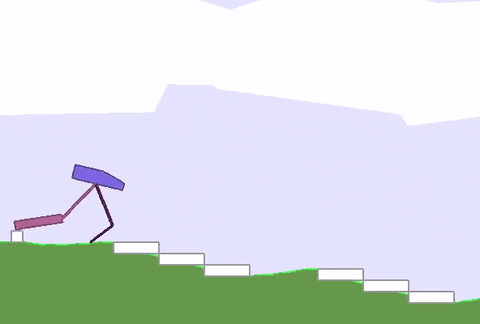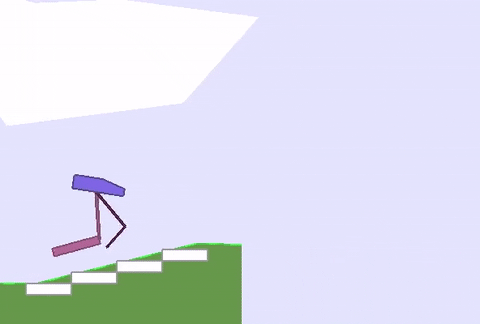
這樣一來,在跨越鴻溝的時候,后腿就能架起一座橋,保護智能體平穩通過,不翻車。
與此同時,前腿承擔了“危險探測器”的責任,偵查前方有怎樣的障礙物,作為“激光雷達”的輔助,可以給后腿的下一步動作提供依據。
重點是,在這副新身材誕生的過程中,AI已學會了通關策略,耗時僅12小時。對比一下,不做身材優化的原始訓練方法,用時長達40小時 (前饋策略網絡,96個GPU) 。
這就是說,優雅的結構加速了智能體的學習過程。
腦洞,并非從天而降
第一,David Ha如何能預感到,改善智能體的結構就可以提升訓練效率?
他說,是從大自然得到了啟發。

有些動物在腦死亡之后,依然可以蹦跳,依然可以游泳。
也就是說,生物體的許多行為,并不依賴大腦。
有種叫做體驗認知 (Embodied Cognition) 的理論認為,認知的許多特征,都不是大腦獨自決定:生物體的方方面面,如運動系統、感知系統、生物體與環境的相互作用等等,都會對認知產生影響。
比如,運動員在長期訓練的過程中,除了身體得到鍛煉,某些特定的心理素質也會隨之生成。
David Ha覺得,這樣的現象在AI身上也有可能發生:對軀體進行訓練,從而影響認知。
第二,通過訓練來改變智能體結構的想法,也是來源于自然。

火烈鳥本不是紅色,吃了小魚小蝦之類的食物,羽毛才變紅
中學生物告訴我們,表現型是基因型與環境共同作用的結果。
那么,各式各樣的虛擬場景,也會讓更適應環境的智能體結構脫穎而出。這樣,AI便可以借助環境的選擇,煉成更加精湛的技能。
緣,妙不可言。

超達科技公眾號

超達商城小程序
咨詢熱線:15890197308技術售后:15890197308郵箱:80410245@qq.com
鄭州超達科技有限公司Copyright ? 2017~2020 All rights reserved.豫ICP備17044048號
網站建設,網站制作,軟件開發,APP開發,小程序開發首選鄭州超達科技,公司擁有超達建站全網營銷系統,是專業的網站建設、網站制作、軟件開發公司,超達建站包含PC網站、手機網站、微信網站,小程序,手機app,一鍵生成,各種終端全覆蓋,操作簡單,任意布局,無需代碼,自由拖拽! 超達科技是一家致力于為政府、企事業單位提供互聯網服務的創新型企業,集軟件定制開發、網站建設、網站優化、網站營銷、網站運維、手機APP開發、微網站制作、系統集成、互聯網應用服務為一體,為企事業單位提供全方位、多平臺一站式服務。

